

сотрудник с 01.01.2019 по 01.01.2025
Россия
ВАК 1.2.1 Искусственный интеллект и машинное обучение
ВАК 1.2.2 Математическое моделирование, численные методы и комплексы программ
В статье описывается внедрение автоматизированного процесса для создания приложений, необходимых при составлении раздела «Гидродинамическое моделирование» проектно-технической документации (ПТД) нефтяных и газовых месторождений. Сегодня такие материалы строятся вручную исполнителем работы. Монотонность выполняемых действий приводит к неизбежным ошибкам в процессе работы. Таким образом, правильно построенная гидродинамическая модель, которая отвечает регламентным требованиям, возвращается на доработку в связи с расхождением параметров в модели и указанных в отчете. Предлагаемые сценарии протестированы более чем на 50 моделях и позволили оптимизировать трудозатраты сотрудников предприятия.
гидродинамическое моделирование, сокращение трудозатрат, автоматизация постобработки результатов, Python-сценарий.
Заключительным этапом гидродинамического моделирования в рамках составления ПТД является выдача результатов моделирования «разработчикам» и подготовка главы для проектного документа. В нефтегазовой отрасли обработка информации у инженеров занимает значительную часть рабочего времени [5, 6]. Наличие инструментов для обработки и анализа данных, а также умение ими пользоваться значительно сокращают временные затраты на процессы постобработки результатов моделирования.
Для составления текста отчета необходимы следующие графические материалы:
-
сопоставление запасов ГМ — ГДМ;
-
данные о свойствах флюидов, принимаемых в модели;
-
сопоставление коэффициента вытеснения модели и принятого к проектированию;
-
сопоставление фактических и расчетных показателей добычи углеводородов;
-
графики сравнения фактических и расчетных показателей;
-
кроссплоты накопленных показателей разработки, а также пластового и забойного давлений [1].
Данные материалы строятся вручную исполнителем работы. При сложном геологическом строении и моделировании объектов, содержащих нефтегазоконденсатную смесь, объем подготавливаемой информации для отчета увеличивается в разы. Монотонность выполняемых действий приводит к неизбежным ошибкам в процессе работы. Таким образом, правильно построенная гидродинамическая модель, которая отвечает регламентным требованиям, возвращается на доработку в связи с расхождением параметров в модели и указанных в отчете.
Несмотря на то, что для подготовки иллюстраций необходимо проводить повторяющиеся действия, каких-либо готовых автоматизированных подходов в современных гидродинамических программных продуктах для формирования регламентных приложений не предусмотрено.
Основной причиной является то, что в научных институтах и нефтяных компаниях есть динамично меняющиеся внутренние регламенты с собственными требованиями к выполняемым работам и итоговые результаты представляются в разных форматах.
Однако по мере популяризации программирования в сфере добычи углеводородов разработчики ПО стали предоставлять возможность с помощью языков программирования упрощать рабочие процессы по созданию и редактированию моделей. При этом код, учитывающий различные геолого-физические особенности объекта разработки, может быть распространен на другие модели без редактирования.
Авторами статьи написаны сценарии для решения рутинных операций, связанных с необходимостью постобработки результатов моделирования. В качестве гидродинамического симулятора был выбран «тНавигатор» от компании «ИРМ». В симуляторе есть необходимый минимум для автоматизации создания регламентных иллюстраций:
-
поддержка скриптов на языке Python,
-
наличие стандартных и ряда пользовательских библиотек для работы с табличными файлами.
Такой функционал позволяет организовать работу по автоматизации внутри предприятия, где более опытный пользователь готовит необходимое решение, а другие пользователи многократно используют это решение, не взаимодействуя непосредственно с кодом.
После инициализации гидродинамической модели необходимо убедиться в корректном задании свойств флюидов и пласта, сравнить значения с данными, указанными в таблице ГФХ.
Авторами предлагается ускорить сравнения данных и автоматизировать выгрузку основных свойств флюидов и породы из ГДМ. Для этого разработан сценарий на языке программирования Python, который выполняет следующие функции: вычисляет необходимые параметры, формирует табличный файл с заданным макетом представления данных, а также вычисляет отклонения. На рисунке 1 представлен фрагмент кода сценария.
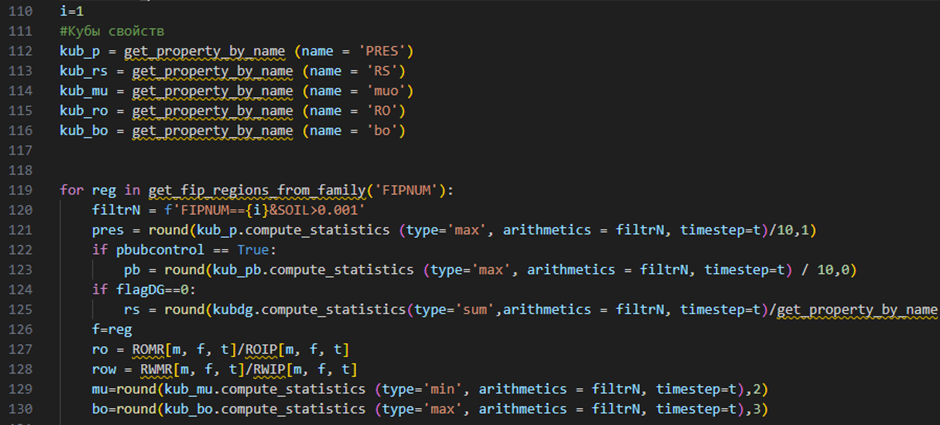
Рисунок 1. Фрагмент кода по выгрузке свойств коллектора
За исключением плотностей, все параметры можно получить напрямую из свойств сетки. Плотности для каждого отчетного региона определяются как отношение массовых запасов к объемным на начало моделирования. На рисунке 2 представлен результат выполнения сценария.
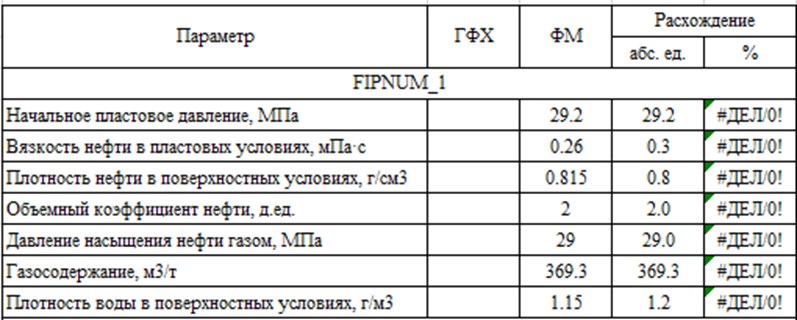
Рисунок 2. Сценарий по выгрузке свойств коллектора
Также необходимо сопоставить начальные геологические запасы углеводородов и подсчетные параметры ГДМ с данными, представленными к утверждению в отчете. Данная процедура была оптимизирована путем написания кода для выгрузки информации в табличный файл и создания оформления.
Напрямую из гидродинамической модели можно получить величину запасов углеводородов, а также значения подсчетных параметров за исключением эффективного и флюидонасыщенного объема. Использование умножения и деления в калькуляторе графиков для объектов типа «свойство сетки» не поддержано симулятором. Вычисление же недостающих объемов через Python путем сложения объема каждой ячейки занимает слишком много времени. Единственным вариантом в такой ситуации является создание карт с эффективным и флюидонасыщенными объемами в графическом интерфейсе симулятора и через написание кода Python обращение к новым «картам».
Стоит отметить, что при обращении к незаданным свойствам гидродинамической модели возникает ошибка. Поэтому при запуске скрипта в первую очередь необходимо обработать ошибки, связанные с возможным отсутствием некоторых данных. Следующим шагом будет создание цикла с проходом по всем отчетным регионам и заполнение массивов данными о запасах и подсчетных параметрах. Затем создается табличный файл, в котором в зависимости от количества фаз и регионов формируется дизайн и происходит заполнение соответствующими значениями. На рисунке 3 представлен фрагмент кода с обработкой ошибок, а также результат выполнения сценария.
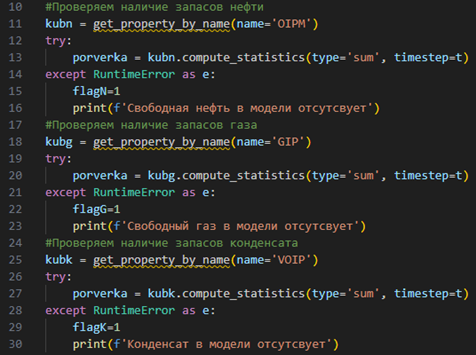 |
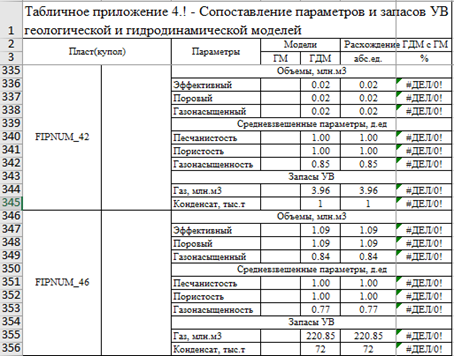 |
Рисунок 3. Сценарий по выгрузке подсчетных параметров: а) фрагмент кода сценария, б) результат
Еще одним рутинным процессом является подготовка данных для оценки качества адаптации гидродинамической модели. Эта задача также была автоматизирована.
Для оценки качества адаптации ГДМ необходимо создать цикл по временным шагам. Затем необходимо взять рассчитанные и исторически накопленные показатели разработки для каждого первого месяца года и добавить их в пользовательский массив. Из накопленных показателей высчитываются годовые, затем определяются отклонения между фактическими и расчетными данными. Следующим шагом является создание нового табличного файла и заполнение ячеек данными из массива. При выполнении цикла на последнем шаге необходимо записать в новый массив основные накопленные показатели по всем скважинам для построения кроссплотов, чтобы оценить качество адаптации поскважинно. На основе полученных данных создаем графики сопоставления фактических и расчетных данных, а также кроссплоты. Заключительным шагом является оформление полученной таблицы и графиков. На рисунке 4 показан результат выполнения сценария.
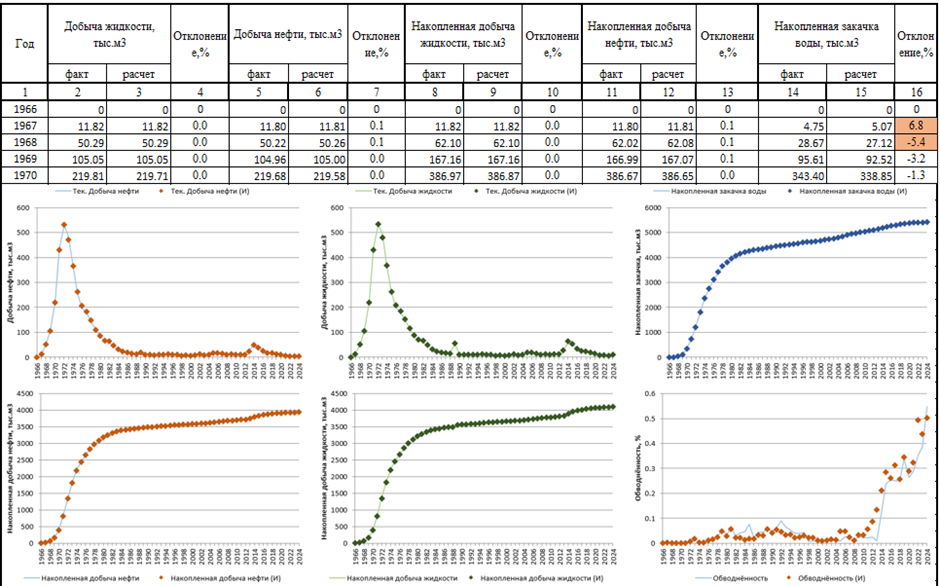
Рисунок 4. Результат работы Сценария для оценки качества адаптации ГДМ
Таким образом, предлагаемые сценарии позволяют распределить объем работы на сотрудников с меньшей квалификацией для формирования текста отчета, тем самым освободив время более опытных сотрудников. Данный набор скриптов упрощает работу экспертизы гидродинамической модели как для исполнителя, так и для эксперта. Оптимизирует затраченное время для формирования регламентных таблиц и исключает технические ошибки. В скриптах используются библиотеки Python, встроенные в «тНавигатор». Это позволяет внедрить скрипт на любой компьютер без дополнительных установочных файлов.
1. Приказ Минприроды России от 20.09.2019 N 639 (ред. от 06.10.2020) «Об утверждении Правил подготовки технических проектов разработки месторождений углеводородного сырья» (Зарегистрировано в Минюсте России 02.10.2019 N 56103).
2. Закревский К. Е. Повышение качества геолого-гидродинамического моделирования / Закревский К. Е., Аржиловский А. В., Тимчук А. С., Грищенко М. А., Бикбулатова Т. Г. // Нефтяное хозяйство. — 2012. — № 10. — С. 44–48.
3. Сыртланов В. Р. К вопросу об автоматизации инженерных методик адаптации гидродинамических моделей нефтяных месторождений / Сыртланов В. Р., Сыртланова В. С., Санников И. Н., Иксанов К. Н // Вестник ЦКР Роснедра. — 2011. — № 4. — С. 31–38.
4. Сыртланов В. Р. О некоторых приемах автоматизации адаптации гидродинамических моделей месторождений углеводородов / Сыртланов В. Р., Головацкий Ю. А., Ишимов И. Н., Межнова Н. И. —Москва, 2019. SPE — 196878. — https://doi.org/10.2118/196878-MS.
5. Иванов А. Н. Применение алгоритма PEXEL для автоматизированной адаптации гидродинамических моделей месторождений / Иванов А. Н., Хисматуллина Ф. С., Аубакиров А. Р., Кургузкина И. В. // Нефт. хоз-во. — 2022. — № 9. — С. 49–52. — https://doi.org/10.24887/0028-2448-2022-9-49-52.
6. Lesslar P. C. Managing Data Assets to Improve Business Performance / Lesslar P. C., van den Berg F. G // SPE Asia Pacific Conference on Integrated Modelling for Asset Management. — Kuala Lumpur, Malaysia, 1998, 23–24 March.